Do you find your Stable Diffusion too slow? Many options to speed up Stable Diffusion is now available. In this article, you will learn about the following ways to speed up Stable Diffusion.
- cross-attention optimization
- Token merging
- Negative guidance minimum sigma
Software
We will use AUTOMATIC1111 Stable Diffusion GUI to create images. You can use this GUI on Google Colab, Windows, or Mac.
Cross-attention optimization options
All optimization options focus on making the cross-attention calculation faster and using less memory. Below are all the options available to you in AUTOMATIC1111.
How to set cross-attention optimization
In AUTOMATIC1111 Web-UI, navigate to the Settings page. Select Optimization on the left panel. In the Cross attention optimization dropdown menu, select an optimization option. The initial selection is Automatic. Click Apply Settings.

Which one should you pick? See the explanation below.
Doggettx
In the early days of Stable Diffusion (which feels like a long time ago), the GitHub user Doggettx made a few performance improvements to the cross-attention operations over the original implementation.
It was a good speed-up then, but people mostly move on to other speed-up options listed below.
xFormers
The attention operation is at the heart of the Stable Diffusion algorithm but is slow.
xFormers is a transformer library developed by the Meta AI team. It speeds up and reduces memory usage of the attention operation by implementing memory-efficient attention and Flash Attention.
Memory-efficient attention computes attention operation using less memory with a clever rearrangement of computing steps. Flash Attention computes the attention operation one small patch at a time. The end result is less memory usage and faster operation.
xFormers is the go-to library before PyTorch implemented a native support. If you have a newer Nvidia video card, you should use SDP instead.
AUTOMATIC1111 command line argument: --xformers
Scaled-Dot-Product (sdp) attention
Scaled dot product attention is Pytorch’s native implementation of memory-efficient attention and Flash Attention. In other words, it is an alternative implementation of the xFormers option.
A drawback of this optimization is that the resulting images can be non-deterministic (a problem in older xFormer versions). You may be unable to reproduce the same image using the same generation parameters.
This is a new function that requires Pytorch 2 or above.
AUTOMATIC1111 command line argument: --opt-sdp-attention
sdp-no-mem
sdp-no-mem is the scaled-dot-product attention without memory-efficient attention.
Unlike SDP attention, the resulting images are deterministic. The same generation parameters produce exactly the same image.
This is a new function that requires Pytorch 2 or above.
AUTOMATIC1111 command line argument: --opt-sdp-no-mem-attention
sub-quadratic attention
Sub-quadratic (sub-quad) attention is yet another implementation of memory-efficient attention, which is part of xFormer and SDP. You can try this option if you cannot use xFormers or SDP.
AUTOMATIC1111 command line argument: --opt-sub-quad-attention
Split-attention v1
Split-attention v1 is an earlier implementation of memory-efficient attention.
You should use xFormers or SDP when turning this on. In AUTOMATIC1111, it is on by default.
AUTOMATIC1111 command line argument: --opt-split-attention-v1
To turn off: --disable-opt-split-attention
Invoke AI
Cross-attention optimization as used in the Invoke AI code base. This option is useful for MacOS users where Nvidia GPU is not available.
Memory management options
Med Vram
Use the command line argument --medvram to conserve GPU memory by only allowing some parts of the model in the VRAM. It slows down the generation a little bit.
Low VRAM
Use the command line argument --lowvram to conserve even more GPU memory by allowing only necessary parts in the VRAM. It drastically slows down the generation.
SDXL settings
Try adding the command line argument –medvram-sdxl or –lowvram experience significant slowdown or cannot run Stable Diffusion XL models. Here are the recommendations.
- Nvidia 12GB+ VRAM:
--opt-sdp-attention - Nvidia 8GB VRAM:
--opt-sdp-attention --medvram-sdxl - Nvidia 4GB VRAM:
--opt-sdp-attention--lowvram - AMD 4GB VRAM:
--lowvram --opt-sub-quad-attention
Token merging
Token merging (ToMe) is a new technique to speed up Stable Diffusion by reducing the number of tokens (in the prompt and negative prompt) that need to be processed. It recognizes that many tokens are redundant and can be combined without much consequence.
The amount of token merging is controlled by the percentage of token merged.
Below are a few samples with 0% to 50% token merging.

A drawback of token merging is it changes the images. You should not turn it on if you want others to reproduce the exact images.
Using token merging in AUTOMATIC1111 WebUI
AUTOMATIC1111 has native support for token merging. You don’t need to install an extension to use it.
To use token merging, navigate to the Settings page. Go to the Optimizations section. Set the token merging ratio. 0.2 means merging 20% of the tokens, for example. Click Apply Settings.
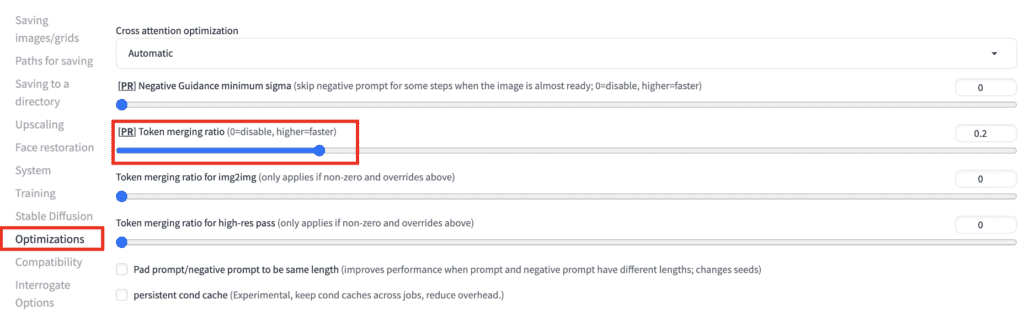
Negative guidance minimum sigma
The Negative guidance minimum sigma option turns off the negative prompt under certain conditions that are believed to be inconsequential. Emprical testing suggests that negative conditioning can be turned off in some steps without affecting the image.

Although changes are small, there are still noticeable minor changes. So don’t use this setting if you want to document the parameters and reproduce exactly the same image later.
Using negative guidance minimum sigma
To use negative guidance minimum sigma, navigate to the Settings page. Go to the Optimizations section. Set the value for the negative guidance minimum sigma. Click Apply Settings.

Speed and memory benchmark
Test setup
Below are the prompt and the negative prompt used in the benchmark test. The exact prompts are not critical to the speed, but note that they are within the token limit (75) so that additional token batches are not invoked.
(close-up editorial photo of 20 yo woman, ginger hair, slim American sweetheart), (freckles:0.8), (lips parted), realistic green eyes, POV, film grain, 25mm, f/1.2, dof, bokeh, beautiful symmetrical face, perfect sparkling eyes, well defined pupils, high contrast eyes, ultra detailed skin
(semi-realistic, cgi, 3d, render, sketch, cartoon, drawing, anime:1.4), text, close up, cropped, out of frame, worst quality, low quality, jpeg artifacts, ugly, duplicate, morbid, mutilated, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, mutation
Model: Chillout Mix
Sampling method: Euler
Size: 512×512
Sampling steps: 20
Batch count: 2
Batch size: 8
CFG Scale: 7
Seed: 100
The following results are from running on an RTX 4090 GPU card and CUDA 11.8.
Benchmark for cross-attention optimization
| Option | Time (sec) | Peak VRAM |
|---|---|---|
| None | 35.1 | 23.1 GB |
| doggettx | 14.4 | 14.9 GB |
| xFormers | 12.8 | 3.5 GB |
| sdp-no-mem | 10.6 | 3.5 GB |
| sdp | 10.5 | 3.5 GB |
| sub-quadratic | 18.8 | 5.9 GB |
| v1 | 21.5 | 3.6 GB |
| Invoke AI | 14.4 | 14.9 GB |
Scaled dot product optimization performs the best, followed by xFormers. Both are good options for speed up and reduced memory usage.
Benchmark for token merging
| Token merge % | Time (sec) | Peak VRAM |
|---|---|---|
| 0 | 10.6 | 3.5 GB |
| 0.3 | 10.3 | 3.5 GB |
| 0.5 | 10.0 | 3.5 GB |
| 0.7 | 9.9 | 3.5 GB |
Token merging improves generation speed, though I don’t find it to be significant.
It does have the potential to alter images substantially. So only use it if you don’t care about reproducibility.

Benchmark for negative guidance minimum sigma
| Negative guidance | Time (sec) | Memory (with reserved) |
|---|---|---|
| 0 | 10.6 | 3.5 GB |
| 0.3 | 10.5 | 3.5 GB |
| 0.5 | 10.2 | 3.5 GB |
| 0.7 | 10.1 | 3.5 GB |
Negative guidance minimum sigma resulted in speed up similar to token merging, but changes the images much less.

Which speed-up option should you use?
If you care about reproducing your images, use xFormers or SDP-no-mem. Don’t use token merging or negative guidance minimum sigma.
If you don’t care about reproducibility, feel free to choose between xFormers, SDP-no-mem and SDP. Use token merging and negative guidance minimum sigma for additional speed up.
If you are on MacOS, Invoke IA is your best bet.
Useful resources
Optimizations · AUTOMATIC1111/stable-diffusion-webui Wiki – Documentation of optimization options from the official AUTOMATIC1111 wiki.
[2303.17604] Token Merging for Fast Stable Diffusion – Research article on token merging.





